

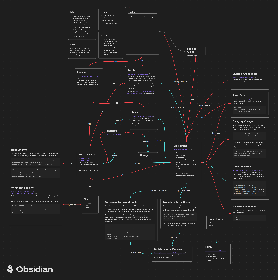
Before I forget here’s the server flow for my 64tb sever. Supports Anime and all the works, never could get manga working with torrent/usenet well enough on ubuntu though.
A short list:
- Anime/Tv/Movies
- Switch games management (kinda)
- Cross Seed
- Unpackerr
- Radarr + Sonarr Queue Cleanup
- Trakt Sync
- Trakt List to add sonarr item (bad practice but whatever)
- Comics (weekly bundles are OP)
- My shitty cronjobs
Make suggestions on improvements, I probably won’t be using this settup on my next server, but similar.
For adding content I used Ombi and the plex watchlist sync feature for those that were leeching on my plex, worked well enough. For better management I used the LunaSea app (great fucking app, go get it now, it’s free)
I didn’t do music bc I have tidal with plex and that’s more then fine, lidarr sucked too much for the artists I like and attempts at streamrip automation failed all the time.
Cronjob abuse is my friend
Forgot to mention this also supports auto-uploading content (with filters) on a cronjob
I would really like to automate my workflow and organize my library, but I like to seed things forever. How do you automatically retrieve metadata to reorganize folders and filenames, while still being able to seed? Is creating a second copy of the files the only way, or is there something I’m missing?
Basically yes. You use *arr to find releases and make a copy with proper naming and metadata when a download finishes. On its own, that would not be great as you would double the size of everything. Except you use hard links. Those are kind of like shortcuts, but both the shortcut and original are the same thing. Both point to the same data on disk. In fact, they’re indistinguishable from each other. If you delete one, the data remains as there is another link pointing to it. If you delete both, the data gets deleted. Basically they are free copies. You just have to make sure your file system supports them
I’ve started reading the guide on the subject. So now my problem is that I have different zfs datasets separating my library, and I suspect hardlinks won’t work across them. So I’ll have to rethink how I organize my filesystem.
Couldn’t have said it much better myself. I think of hardlinks like backend and front end development offices.
The backend team has the data that frontend teams 1 & 2 use, but frontend team 3 isn’t in the same office (filesystem) as the backend team so they can’t access the data.
If frontend team 2 goes down, frontend team 1 still has access to the backend’s data
Writing new data: teams 1 and 2 go down then fuckit we can bulldoze backend and make a new backend for any new frontend teams.





{kind=link}
{kind=link}