


{kind=link}
{kind=link}
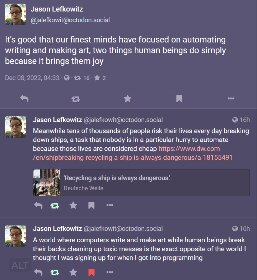
Could you give me an example that uses live feeds of video data, or feeds the output to another system? As far as I’m aware (I could be very wrong! Not an expert), the only things that come close to that are things like OCR systems and character recognition. Describing in machine-readable actionable terms what’s happening in an image isn’t a thing, as far as I know.
No live video no, that didn’t seem the topic
But if you had the horsepower, I don’t think it’s impossible based on what I’ve worked with. It’s just about snipping and distributing the images, from a bottleneck standpoint
Describing in machine-readable actionable terms what’s happening in an image isn’t a thing, as far as I know.
It is. That’s actually the basis of multimodal transformers - they have a shared embedding space for multiple modes of data (e.g. text and images). If you encode data and take those embeddings, you suddenly have a vector describing the contents of your input.