

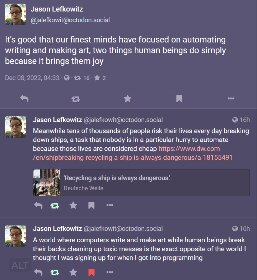
Well, this is simply incorrect. And confidently incorrect at that.
Vision transformers (ViT) is an important branch of computer vision models that apply transformers to image analysis and detection tasks. They perform very well. The main idea is the same, by tokenizing the input image into smaller chunks you can apply the same attention mechanism as in NLP transformer models.
ViT models were introduced in 2020 by Dosovitsky et. al, in the hallmark paper “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” (https://arxiv.org/abs/2010.11929). A work that has received almost 30000 academic citations since its publication.
So claiming transformers only improve natural language and vision output is straight up wrong. It is also widely used in visual analysis including classification and detection.

{kind=link}
{kind=link}
Thank you for the correction. So hypothetically, with millions of hours of GoPro footage from the scuttle crew, and if we had some futuristic supercomputer that could crunch live data from a standard definition camera and output decisions, we could hook that up to a Boston dynamics style robot and run one replaced member of the crew?