


Also linear algebra and vector calculus

or stolen data

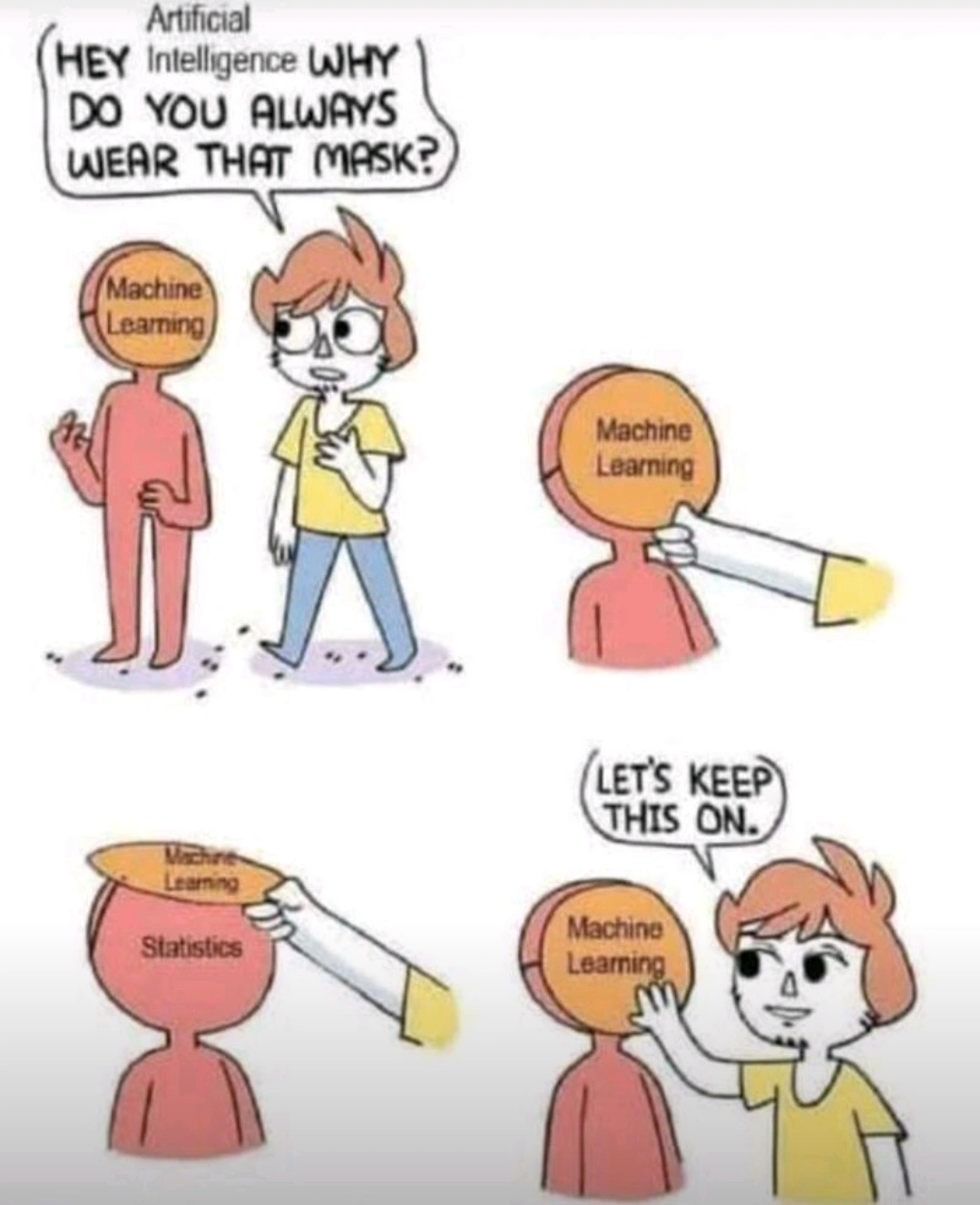
Neural nets, including LLMs, have almost nothing to do with statistics. There are many different methods in Machine Learning. Many of them are applied statistics, but neural nets are not. If you have any ideas about how statistics are at the bottom of LLMs, you are probably thinking about some other ML technique. One that has nothing to do with LLMs.
Software developer here, the more I learn about neural networks, the more they seem like very convoluted statistics. They also just a simplified form of neurons, and thus I advise against overhumanization, even if they’re called “neurons” and/or Alex.
That’s where the almost comes in. Unfortunately, there are many traps for the unwary stochastic parrot.
Training a neural net can be seen as a generalized regression analysis. But that’s not where it comes from. Inspiration comes mainly from biology, and also from physics. It’s not a result of developing better statistics. Training algorithms, like Backprop, were developed for the purpose. It’s not something that the pioneers could look up in a stats textbook. This is why the terminology is different. Where the same terms are used, they don’t mean quite the same thing, unfortunately.
Many developments crucial for LLMs have no counterpart in statistics, like fine-tuning, RLHF, or self-attention. Conversely, what you typically want from a regression - such as neatly interpretable parameters with error bars - is conspicuously absent in ANNs.
Any ideas you have formed about LLMs, based on the understanding that they are just statistics, are very likely wrong.
“such as neatly interpretable parameters”
Hahaha, hahahahahaha.
Hahahahaha.
That book probably doesn’t go much further than neural networks with 1 hidden layer. Maybe 2 hidden layers at most.
IMO, statistics is about explaining data. Regression is useful to explain how parameters relate to each others. Statistics that don’t help us understand data isn’t useful statistics.
Modern machine learning has strayed far away from data explanation. Now it’s common to deal with more than a dozen hidden layers. It might have roots in statistics, but mostly it’s about brute forcing any curve to the data. It doesn’t help us understanding the data better, but at least we have approximated some function.
If you have any ideas about how statistics are at the bottom of LLMs, you are probably thinking about some other ML technique.
It might have roots in statistics
Care to reiterate?
Well, lots of people blinded by hype here… Obv it is not simply statistical machine, but imo it is something worse. Some approximation machinery that happen to work, but gobbles up energy in cost. Something only possible becauss we are not charging companies enough electricity costs, smh.
We’re in the “computers take up entire rooms in a university to do basic calculations” stage of modern AI development. It will improve but only if we let them develop.
Moore’s law died a long time ago, and AI models aren’t getting any more power efficient from what I can tell.
Yeah, and improvements will require paradigm changes. I don’t see that from GPT.
Honestly if this massive energy need for AI will help accelerate modular/smaller nuclear reactors 'm all for it. With some of these insane data centers companies want to build each one will need their own power plants.
I’ve seen tons of articles on small/modular reactor companies but never seen any make it to the real world yet.
This is exactly how I explain the AI (ie what the current AI buzzword refers to) tob common folk.
And what that means in terms of use cases.
When you indiscriminately take human outputs (knowledge? opinions? excrements?) as an input, an average is just a shitty approximation of pleb opinion.



{kind=link}
{kind=link}