

Previous posts: https://programming.dev/post/3974121 and https://programming.dev/post/3974080
Original survey link: https://forms.gle/7Bu3Tyi5fufmY8Vc8
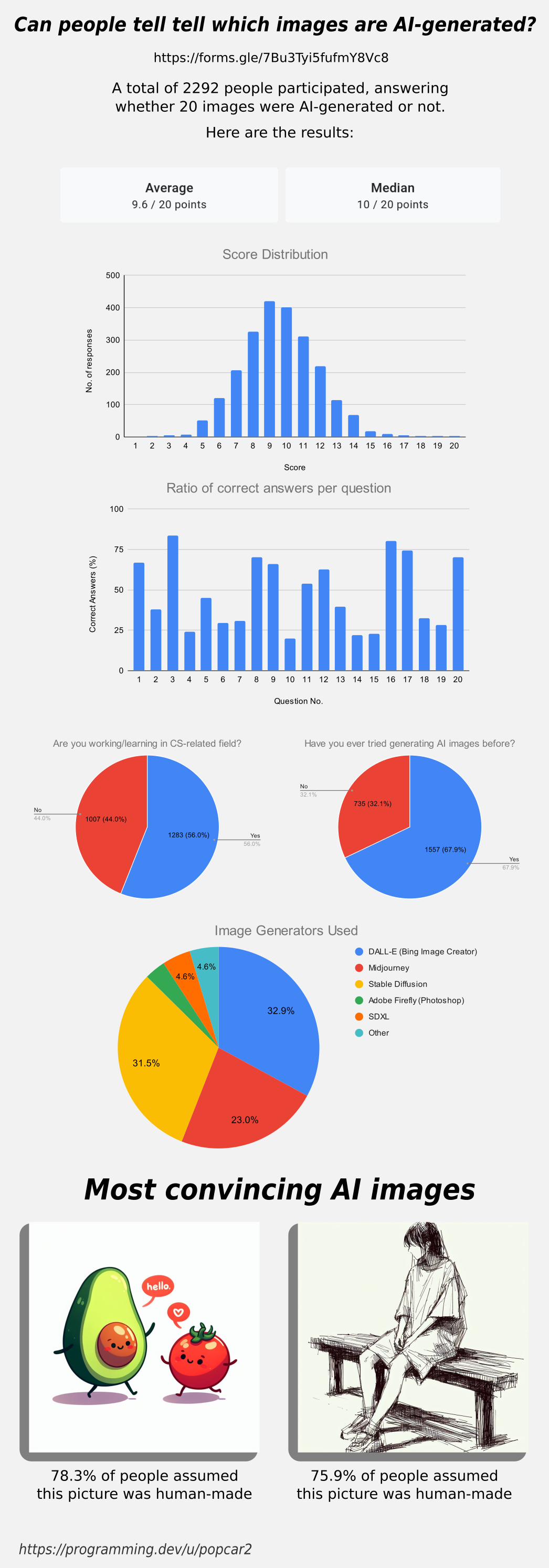
Thanks for all the answers, here are the results for the survey in case you were wondering how you did!
Edit: People working in CS or a related field have a 9.59 avg score while the people that aren’t have a 9.61 avg.
People that have used AI image generators before got a 9.70 avg, while people that haven’t have a 9.39 avg score.
Edit 2: The data has slightly changed! Over 1,000 people have submitted results since posting this image, check the dataset to see live results. Be aware that many people saw the image and comments before submitting, so they’ve gotten spoiled on some results, which may be leading to a higher average recently: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
So if the average is roughly 10/20, that’s about the same as responding randomly each time, does that mean humans are completely unable to distinguish AI images?
In theory, yes. In practice, not necessarily.
I found that the images were not very representative of typical AI art styles I’ve seen in the wild. So not only would that render preexisting learned queues incorrect, it could actually turn them into obstacles to guessing correctly pushing the score down lower than random guessing (especially if the images in this test are not randomly chosen, but are instead actively chosen to dissimulate typical AI images).
I would also think it depends on what kinds of art you are familiar with. If you don’t know what normal pencil art looks like, how are ya supposed to recognize the AI version.
As an example, when I’m browsing certain, ah, nsfw art, I can recognize the AI ones no issue.
Agreed. For the image that was obviously an emulation of Guts from Berserk, the only reason I called it as AI generated was because his right eye was open. I don’t know enough about illustration in general, which led me to guess quite a few incorrect examples there.
I found the photos much easier, and I guessed each of those correctly just by looking for the sort of “melty” quality you get with most AI generated photos, along with intersected line continuity (e.g. an AI probably would have messed up this image where the railing overlaps the plant stems; the continuity made me accept it as real). But with illustrations, I don’t know nearly enough about composition and technique, so I can’t tell if a particular element is “supposed” to be there or not. I would like to say that the ones I correctly called as AI were still moderately informed because some of them had that sort of AI-generated color balance/bloom to them, but most of them were still just coin toss to me.
Maybe you didn’t recognize the AI images in the wild and assumed they were human made. It’s a survival bias; the bad AI pictures are easy to figure out, but we might be surrounded by them and would not even know.
Same as green screens in movies. It’s so prevalent we don’t see them, but we like to complain a lot about bad green screens. Every time you see a busy street there’s a 90+ % chance it’s a green screen. People just don’t recognize those.


If you look at the ratios of each picture, you’ll notice that there are roughly two categories: hard and easy pictures. Based on information like this, OP could fine tune a more comprehensive questionnaire to include some photos that are clearly in between. I think it would be interesting to use this data to figure out what could make a picture easy or hard to identify correctly.
My guess is that a picture is easy if it has fingers or logical structures such as text, railways, buildings etc. while illustrations and drawings could be harder to identify correctly. Also, some natural structures such as coral, leaves and rocks could be difficult to identify correctly. When an AI makes mistakes in those areas, humans won’t notice them very easily.
The number of easy and hard pictures was roughly equal, which brings the mean and median values close to 10/20. If you want to bring that value up or down, just change the number of hard to identify pictures.
The number of easy and hard pictures was roughly equal, which brings the mean and median values close to 10/20.
This is true if “hard” means “it’s trying to get you to make the wrong answer” as opposed to “it’s so hard to tell, so I’m just going to guess.”
That’s a very important distinction. Hard wasn’t the clearest word for that use. I guess I should have called it something else such as deceptive or misleading. The idea is that some pictures got a below 50% ratio, which means that people were really bad at categorizing them correctly.
There were surprisingly few pictures that were close to 50%. Maybe it’s difficult to find pictures that make everyone guess randomly. There are always a few people who know what they’re doing because they generate pictures like this on a weekly basis. The answers will push that ratio higher.

It depends on if these were hand picked as the most convincing. If they were, this can’t be used a representative sample.

But you will always hand pick generated images. It’s not like you hit the generate button once and call it a day, you hit it dozens of times tweaking it until you get what you want. This is a perfectly representative sample.

As a personal example, this is what I generated and after like few hours of tweaking, regenerating and inpainting, this was the final result. And here’s another: initial generation, the progress animation, and end result.
Are they perfect, no, but the really obvious bad AI art comes from people who expect it to spit perfect images at you.
One thing I’m not sure if it skews anything, but technically ai images are curated more than anything, you take a few prompts, throw it into a black box and spit out a couple, refine, throw it back in, and repeat. So I don’t know if its fair to say people are getting fooled by ai generated images rather than ai curated, which I feel like is an important distinction, these images were chosen because they look realistic
Well, it does say “AI Generated”, which is what they are.
All of the images in the survey were either generated by AI and then curated by humans, or they were generated by humans and then curated by humans.
I imagine that you could also train an AI to select which images to present to a group of test subjects. Then, you could do a survey that has AI generated images that were curated by an AI, and compare them to human generated images that were curated by an AI.
All of the images in the survey were either generated by AI and then curated by humans, or they were generated by humans and then curated by humans.
Unless they explained that to the participants, it defeats the point of the question.
When you ask if it’s “artist or AI”, you’re implying there was no artist input in the latter.
The question should have been “Did the artist use generative AI tools in this work or did they not”?
I mean fair, I just think that kind of thing stretches the definition of “fooling people”
LLMs are never divorced from human interaction or curation. They are trained by people from the start, so personal curation seems like a weird caveat to get hung up on with this study. The AI is simply a tool that is being used by people to fool people.
To take it to another level on the artistic spectrum, you could get a talented artist to make pencil drawings to mimic oil paintings, then mix them in with actual oil paintings. Now ask a bunch of people which ones are the real oil paintings and record the results. The human interaction is what made the pencil look like an oil painting, but that doesn’t change the fact that the pencil generated drawings could fool people into thinking they were an oil painting.
AIs like the ones used in this study are artistic tools that require very little actual artistic talent to utilize, but just like any other artistic tool, they fundamentally need human interaction to operate.
But not all AI generated images can fool people the way this post suggests. In essence this study then has a huge selection bias, which just makes it unfit for drawing any kind of conclusion.
Technically you’re right but the thing about AI image generators is that they make it really easy to mass-produce results. Each one I used in the survey took me only a few minutes, if that. Some images like the cat ones came out great in the first try. If someone wants to curate AI images, it takes little effort.
I think if you consider how people will use it in real life, where they would generate a bunch of images and then choose the one that looks best, this is a fair comparison. That being said, one advantage of this kind of survey is that it involves a lot of random, one-off images. Trying to create an entire gallery of images with a consistent style and no mistakes, or trying to generate something that follows a design spec is going to be much harder than generating a bunch of random images and asking whether or not they’re AI.
Did you not check for a correlation between profession and accuracy of guesses?
I have. Disappointingly there isn’t much difference, the people working in CS have a 9.59 avg while the people that aren’t have a 9.61 avg.
There is a difference in people that have used AI gen before. People that have got a 9.70 avg, while people that haven’t have a 9.39 avg score. I’ll update the post to add this.

Can we get the raw data set? / could you make it open? I have academic use for it.
Sure, but keep in mind this is a casual survey. Don’t take the results too seriously. Have fun: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
Do give some credit if you can.
If you do another one of these, I would like to see artist vs non-artist. If anything I feel like they would have the most experience with regular art, and thus most able to spot incongruency in AI art.
I don’t feel that’s true coming from more “traditional” art circles. From my anecdotal experience, most people can’t tell AI art from human art, especially digital and the kind the examples are from - meaning, hobbyist/semi-pro/pro deviant art type stuff. The examples seem obviously hand picked from both non-AI and AI-side to eliminate any differences as far as possible. And I feel both, the inability to tell the difference and the reason the dataset is what it is is because, well, they’re very similar, mainly because the whole deviant art/art station/whatever scene is a masssssive part of the dataset they use to train these Ai-models, closing the gap even further.
I’m even a bit of a stickler when it comes to using digital tools and prefer to work with pens and paints as far as possible, but I flunked out pretty bad, but then again I can’t really stand this deviant art type stuff so I’m not a 100% familiar, a lot of the human made ones look very AI.
I’d be interested in seeing the same, artist vs. non-artist survey, but honestly I feel it’s the people more familiar with specifically AI-generated art that can tell them apart the best. They literally specifically have to learn (if you’re good at it) to spot the weird little AI-specific details and oopsies to not make it look weird and in the uncanny valley.
I still don’t believe the avocado comic is one-shot AI-generated. Composited from multiple outputs, sure. But I have not once seen generative AI produce an image that includes properly rendered text like this.
Bing image creator uses the new DALL-E model which does hands and text pretty good.
generated this first try with the prompt a cartoon avocado holding a sign that says ‘help me’
Image generation tech has gone crazy over the past year and a half or so. At the speed it’s improving I wouldn’t rule out the possibility.
Here’s a paper from this year discussing text generation within images (it’s very possible these methods aren’t SOTA anymore – that’s how fast this field is moving): https://openaccess.thecvf.com/content/WACV2023/html/Rodriguez_OCR-VQGAN_Taming_Text-Within-Image_Generation_WACV_2023_paper.html


Its Dalle 3 its not that difficult to generate something like that using dalle 3 here’s some shreks I generated as a showcase Shrek 1 inage
All of these are just generated nothing else
Its not that difficult to generate something like that using dalle 3 here’s some shreks I generated as a showcase Shrek 1 inage
All of these are just generated nothing else
Prompt and tool links? I know there are tools that try to pick out label text in the prompt and composite it after the fact, but I don’t consider this one-shot AI generated, even if it’s a single tool from the user’s perspective.
Its Dalle 3 like I said. As far as in aware Dalle 3 doesn’t do that since the text isn’t always perfect still. Can’t really provide prompts since its been a bit, and the history on it isn’t great, but I was just mostly shrek in x style and saying “x” do mind you Dalle is very heavily censored now, so you’re now unlikely to be able to recreate that.
It’s on - https://bing.com/create
Something I’d be interested in is restricting the “Are you in computer science?” question to AI related fields, rather than the whole of CS, which is about as broad a field as social science. Neural networks are a tiny sliver of a tiny sliver




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}