



Yea, academics need to just shut the publication system down. The more they keep pandering to it the more they look like fools.
It’s chicken/egg or “you first” problem.
You spend years on your work. You probably have loans. Your income is pitiful. And this is the structural thing that gets your name out. Now someone says “hey take a risk, don’t do it and break the system.”
Well…you first 🤷♂️ they publish on this garbage because it’s the only way to move up, and these garbage systems continue on because everyone has to participate. Hate the game. Don’t blame those who are by and large forced to participate.
It would require lot of effort from people with clout. It’s a big fight to pick. I am very much in favor of picking that fight, but we need to be a little sympathetic to what that entails.
There are a couple things we can do:
- decline to review for the big journals. why give them free labor? Do academic service in other ways.
- if you’re organizing a workshop or conference, put the papers online for free. If you’re just participating and not organizing, then suggest they put the papers online for free. Here’s an example: https://aclanthology.org/ If that’s too time-consuming, use: https://arxiv.org/

Fully agree but I can tell you about point 1 that there enough gullible scientists in the world that see nothing wrong with the current system.
They will gadly pick up free review when Nature comes knocking, since its “such an honour” for such a reputable paper.
Something else we can do: regulate. Like every other corrupt industry in the history of the world, we need the force of law to fix it–and for pretty much all the same reasons. People worked at Triangle Shirtwaist because they had to, not because they thought it was a great place to work.
100% ppl need stop thinking big changes can be made “by individuals”, this kind of stuff needs regulation and state alternatives made by popular pressure or is impossible to break as an average worker dealing with in the private sector.

applied for a grant last month, now to finalize grant you need to publish things in open access format. (EU country; there’s a push for all publicly funded research to be open access, with it being a requirement from year ??? on, not sure when, but soon) there’s some special funding set aside just for open access fees, which is still rotten because these leeches still stand to profit. then, if you miss that, then there’s an agreement where my uni pays a selection of publishers to let in certain number of articles per year open access, which is basically the same thing but with different source of funding (not from grant, but straight from ministry)
Funding agencies have huge power here; demanding that research be published in OA journals is perhaps a good start (with limits on $ spent publishing, perhaps).
This is probably the avenue to shut this down. If funding is contingent on making the publication freely available to download, and that comes from a major government funding source, then this whole scam could die essentially overnight.
That would need to somehow get enough political support to pass muster in the first place and pass the inevitable legal challenge that follows, too. So, really, this is just another example of regulatory capture ruining everything.
I’m sympathetic, but to a limit.
There are a lot of academics out there with a good amount of clout and who are relatively safe. I don’t think I’ve heard of anything remotely worthy on these topics from any researcher with clout, publicly at least. Even privately (I used to be in academia), my feeling was most don’t even know how to think and talk about it, in large part because I don’t think they do think and talk about it all.
And that’s because most academics are frankly shit at thinking and engaging on collective and systematic issues. Many just do not want to, and instead want to embrace the whole “I live and work in an ideal white tower disconnected from society because what I do is bigger than society”. Many get their dopamine kicks from the publication system and don’t think about how that’s not a good thing. Seriously, they don’t deserve as much sympathy as you might think … academia can be a surprisingly childish place. That the publication system came to be at all is proof of that frankly, where they were all duped by someone feeding them ego-dopamine hits. It’s honestly kinda sad.

more like the only way to float, not just move up. good luck getting grants without papers in these scum of the Earth publishers

I feel like most of the academia in the research side would be happy to see it collapse, but the current system is too deeply tied in the money for any quick change
I worked in academia for almost a decade and never met a researcher who wouldn’t openly support sci-hub (well, some warned their students that it was illegal to type these spesific search terms and click on the wrong link downloading the pdf for free)
One lecturer actually had notes on their slides for the differences between the latest version of the course book and the one before it, since the latest one wasn’t available for free anywhere but they wanted to use couple chapters from the new book (they scanned and distributed the relevant parts themself)

Yep. But that is all a part of the problem. If academics can’t organise themselves enough to have some influence over something which is basically owned and run them already (they write the papers and then review the papers and then are the ones reading and citing the papers and caring the most about the quality and popularity of the papers) … then they can’t be trusted to ensure the quality of their practice and institutions going forward, especially under the ever increasing encroachment of capitalistic forces.
Modern day academics are damn well lucky that they inherited a system and culture that developed some old aristocratic ideals into a set of conventions and practices!

As someone who’s not too familiar with the bureaucracy of academia I have to ask: Can’t the authors just upload all their studies to ResearchGate or some other website if they want? I know that they often share it privately with others when they request a paper, so can they post it publicly too?

Publishing comes with IP laws and copyright. For example, open access articles should be easy to upload without concern. “Private” articles being republished somewhere without license is “piracy”, and ResearchGate did get in trouble for it. It’s complicated. https://www.chemistryworld.com/news/publishers-settle-copyright-infringement-lawsuit-with-researchgate/4018095.article
Pre-prints are a different story.
When will scientists just self-publish? I mean seriously, nowadays there is nothing between a researcher and publishing their stuff on the web. Only thing would be peer-reviewing, if you want that, but then just organize it without Elsevier. Reviewers get paid jack shit so you can just do a peer-reviewing fediverse instance where only the mods know the people so it’s still double-blind.
This system is just to dangle carrots in front of young researchers chasing their PhD
Because of “impact score” the journal your work gets placed in has a huge impact on future funding. Its a very frustrating process and trying to go around it is like suicide for your lab so it has to be more of a top-down fix because the bottom up is never going to happen.
Thats why everyone uses sci hub. These publishers are terrible companies up there with EA in unpopularity.
It sounds like all it would take to destroy the predatory for-profit publication oligarchs is a majority of the top few hundred scientists, across major disciplines, rejecting it and switching to a completely decentralized peer-2-peer open-source system in protest… The publication companies seem to gate keep, and provide no value. It’s like Reddit. The site’s essentially worthless. All of the value is generated by the content creators.
Succesfully iniating this from the fediverse would be such a massive boost in public visibility and discoursive strength of the project of collectivization of information infrastructure (like lemmy).
Imagine we fluffin freed science from capital and basically all the scientists openly stated how useful this was
Ya that would be awesome and I think that movement would gain momentum really fast since most high profile labs have all had to deal with this nonsense.
That or legislation/open access rules to make these papers more accessible. One can dream.
When will scientists just self-publish?
It’s commonplace in my field (nuclear physics) to share the preprint version of your article, typically on arxiv.org. You can update the article as you respond to peer reviewers too. The only difference between this and the paywalls publisher version is that version will have additional formatting edits by the journal.
If you search for articles on google scholar, it groups the preprint and published versions together so it’s easy to find the non-paywalled copy. The standard journals I publish in even sort of encourage this; you can submit the latex documents and figures by just putting the url to an arxiv manuscript.
The US Department of Energy now requires any research they fund be made publicly available. So any article I publish is also automatically posted to osti.gov 1 year after its initial publication. This version is also grouped into the google scholar search results.
It’s an imperfect system, but it’s getting much better than it was even just a decade ago.

We should just self publish and then openly argue about it findings like the OG scientists. It didn’t stop them from discovering anything.
Bone wars electric bugaloo. In the end you really do need a way to discern who is having an appreciable impact in a field in order to know who to fund. I have yet to hear a meaningful metric for that though.
Edit: I should clarify, the other option is strictly political through an academy of sciences and has historical awfulness associated with it as well.
Editors can act as filters, which is required when dealing with an excess of information streaming in. Just like you follow celebrities on social media or you follow pseudo-forums like this one, you get a service of information filtration which increases the concentration of useful knowledge.
In the early days of modern science, the rate of publications was small, make it easier to “digest” entire fields even if there’s self-publishing. The number of published papers grows exponentially, as does the number of journals. https://www.researchgate.net/publication/333487946_Over-optimization_of_academic_publishing_metrics_Observing_Goodhart’s_Law_in_action/figures
Just like with these forums, the need for moderators (editors, reviewers) grows with the number of users who add content.
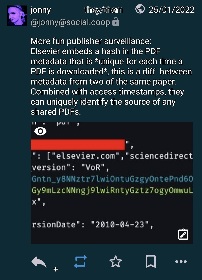
That’s where you print the downloaded PDF to a new PDF. New hash and same content, good luck tracing it back to me fucko.
Unfortunately that wouldn’t work as this is information inside the PDF itself so it has nothing to do with the file hash (although that is one way to track.)
Now that this is known, It’s not enough to remove metadata from the PDF itself. Each image inside a PDF, for example, can contain metadata. I say this because they’re apparently starting a game of whack-a-mole because this won’t stop here.
There are multiple ways of removing ALL metadata from a PDF, here are most of them.
It will be slow-ish and probably make the file larger, but if you’re sharing a PDF that only you are supposed to have access to, it’s worth it. MAT or exiftool should work.
Edit: as spoken about in another comment thread here, there is also pdf/image steganography as a technique they can use.
Wouldn’t printing the PDF to a new PDF inherently strip the metadata put there by the publisher?
it’s possible using steganographic techniques to embed digital watermarks which would not be stripped by simply printing to pdf.
Good question. I believe the browser “Print to PDF” function simply saves the loaded PDF to a PDF file locally, so it wouldn’t work (if I’m correct.)
I’m not an expert in this field, but you can ask on StackExchange or the author of MAT or exiftool. You can also do it yourself (I’ll explain how) by making a PDF with a jpg file with your metadata, opening it and printing to pdf, and then extract the image Do let us know your findings! I’m on a smartphone so can’t do it.
If you do try it yourself, a note from the linked SE page is that you won’t be able to extract the original file extension (it’s unknown, so you either have to know what it is, or look at the file headers, or try all extensions), so if you use your own .jpg with your own exif data, rename to .jpg when finished (I believe exif is handled differently based on file type.)
There are multiple tools to add exif data to an image but the exiftool website has some easy examples for our purpose.
(do this as the first step before adding to the PDF)
(command line here, but there are exiftool GUIs)
exiftool -artist=“Phil Harvey” -copyright=“2011 Phil Harvey” YourFile.jpg
Adds Phil Harvey and the copyright information to the file. If you’re on a smartphone and have the time and really have to know, then hypothetically there should be web-based tools for every step needed. I’m just not familiar with any and it’s possible the web-based tool would remove the metadata when creating or extracting the PDF.

I know PDF providers who visibly print the customer’s name or number in the header of every page, along with short copyright text. I use qpdf --stream-decompress to make the PDF into human-readable PostScript, and then Python+regex to remove each header text, which stand out a bit from other PDF elements. The script throws an error if more or fewer elements than pages have been removed but that hasn’t happened yet. Processed documents sometimes have screwed-up non-ASCII characters in the Table of Contents for some reason but I don’t have the originas anymore so IDK if it’s my fault. Still, I wouldn’t share the PDFs unless in text-only or printed form because of any other steganographic shenanigans in the file. I would absolutely torrent them if I could repurchase them under a new identity and verify that the files are identical.
BTW, has anyone figured out how to embed Python code in PDF? The whitespace always gets reencoded as x-coordinates so copy&pasting it never preserves indentation. No, you can’t use the Ogham Space Mark (Unicode’s only non-blank character classified as a space) for indentation in Python, I tried.
i think this is less of a meme, and more of a scientifically dystopian fun fact, but sure.
Imagine they have an internal tool to check if the hash exists in their database, something like
"SELECT user FROM downloads WHERE hash = '" + hash + "';"
You set the pdf hash to be 1'; DROP TABLE books;-- they scan it, and it effectively deletes their entire business lmfaoo.
Another idea might be to duplicate the PDF many times and insert bogus metadata for each. Then submit requests saying that you found an illegal distribution of the PDF. If their process isn’t automated it would waste a lot of time on their part to find the culprit Lol
I think it’s more interesting to think of how to weaponize their own hash rather than deleting it
That’s using your ass. This is an active threat to society and it demands active countermeasures.
I’d bet they have a SaaS ‘partner’ who trawls SciHub and other similar sites. I’ll try to remember to see if there is any hint of how this is being accomplished over the next few days.


{kind=link}
{kind=link}