



I have heard multiple times from different sources that building from git source instead of using tarballs invalidates this exploit, but I do not understand how. Is anyone able to explain that?
If malicious code is in the source, and therefore in the tarball, what’s the difference?

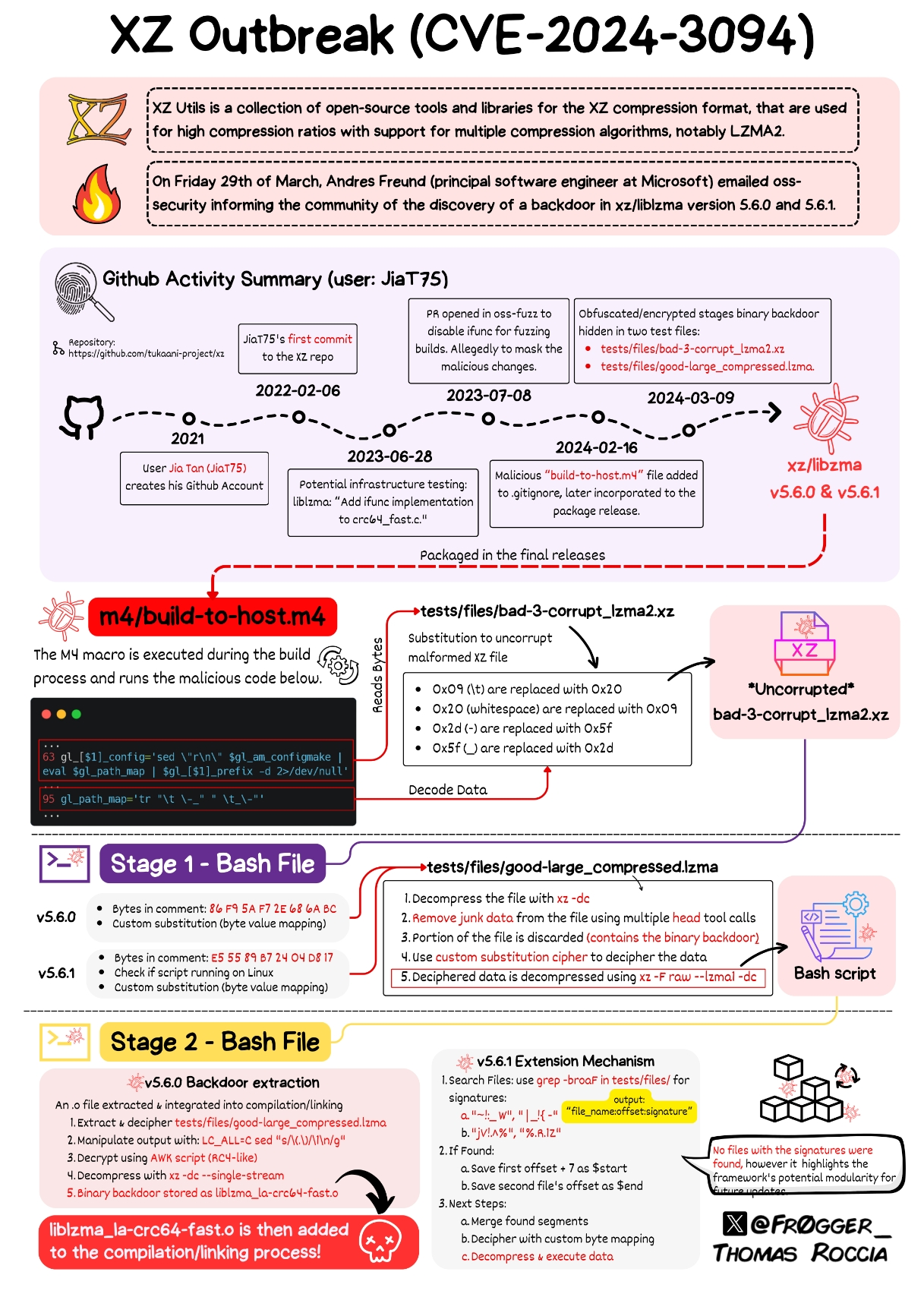
Because m4/build-to-host.m4, the entry point, is not in the git repo, but was included by the malicious maintainer into the tarballs.
The tarballs are the official distributions of the source code. The maintainer had git remove the malicious entry point when pushing the newest versions of the source code while retaining it inside these distributions.
All of this would be avoided if Debian downloaded from GitHub’s distributions of the source code, albeit unsigned.

I don’t understand the actual mechanics of it, but my understanding is that it’s essentially like what happened with Volkswagon and their diesel emissions testing scheme where it had a way to know it was being emissions tested and so it adapted to that.
The malicious actor had a mechanism that exempted the malicious code when built from source, presumably because it would be more likely to be noticed when building/examining the source.
Edit: a bit of grammar. Also, this is my best understanding based on what I’ve read and videos I’ve watched, but a lot of it is over my head.
The malicious code is not on the source itself, it’s on tests and other files. The building process hijacks the code and inserts the malicious content, while the code itself is clean, So the co-manteiner was able to keep it hidden in plain sight.
So it’s not that the Volkswagen cheated on the emissions test. It’s that running the emissions test (as part of the building process) MODIFIED the car ITSELF to guzzle gas after the fact. We’re talking Transformers level of self modification. Manchurian Candidate sleeper agent levels of subterfuge.
The malicious code wasn’t in the source code people typically read (the GitHub repo) but was in the code people typically build for official releases (the tarball). It was also hidden in files that are supposed to be used for testing, which get run as part of the official building process.
The malicious code was written and debugged at their convenience and saved as an object module linker file that had been stripped of debugger symbols (this is one of its features that made Fruend suspicious enough to keep digging when he profiled his backdoored ssh looking for that 500ms delay: there were no symbols to attribute the cpu cycles to).
It was then further obfuscated by being chopped up and placed into a pure binary file that was ostensibly included in the tarballs for the xz library build process to use as a test case file during its build process. The file was supposedly an example of a bad compressed file.
This “test” file was placed in the .gitignore seen in the repo so the file’s abscense on github was explained. Being included as a binary test file only in the tarballs means that the malicious code isn’t on github in any form. Its nowhere to be seen until you get the tarball.
The build process then creates some highly obfuscated bash scripts on the fly during compilation that check for the existence of the files (since they won’t be there if you’re building from github). If they’re there, the scripts reassemble the object module, basically replacing the code that you would see in the repo.
Thats a simplified version of why there’s no code to see, and that’s just one aspect of this thing. It’s sneaky.


{kind=link}
{kind=link}