


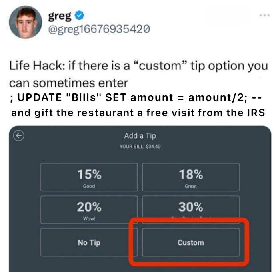
Yup. Rand() chooses a random float value for each entry. By default I believe it’s anywhere between 0 and 1. So it may divide the first bill by .76, then the second by .23, then the third by 0.63, etc… So you’d end up with a completely garbage database because you can’t even undo it by multiplying all of the numbers by a set value.

Also, by dividing by a number between 0 and 1, you increase the amount it looks like it billed. So income will look like it’s higher than outgoing funds, which will raise suspicions of embezzlement. And if someone actually is embezzling, whatever accounting tricks they’ve been using to hide it might just stop working because everything might need to be examined with a fine tooth comb. “Oh, the billing numbers aren’t right, and also it turns out the invoice numbers aren’t right either. Billing issue was tracked to a hack, but what’s going on with these invoices?”
if you’re trying to be malicious, wouldn’t it be better to multiply by Rand() instead of divide by Rand()?
assuming there are a decent number of recorded sales, you’d end up seeing many of the calls to Rand() returning values very close to 0. so, if you’re dividing by those values, you’d end see lots of sales records reporting values in the thousands, millions, or even billions of dollars. i feel like that screams “software bug” more than anything. on the other hand, seeing lots of values multiplied by values close to 0 would certainly look weird, but it wouldn’t be as immediately suspicious.
(of course a better thing would just be to use Rand() on a range other than [0,1])



{kind=link}
{kind=link}