



Thank you open source for the transparency.


I have heard multiple times from different sources that building from git source instead of using tarballs invalidates this exploit, but I do not understand how. Is anyone able to explain that?
If malicious code is in the source, and therefore in the tarball, what’s the difference?

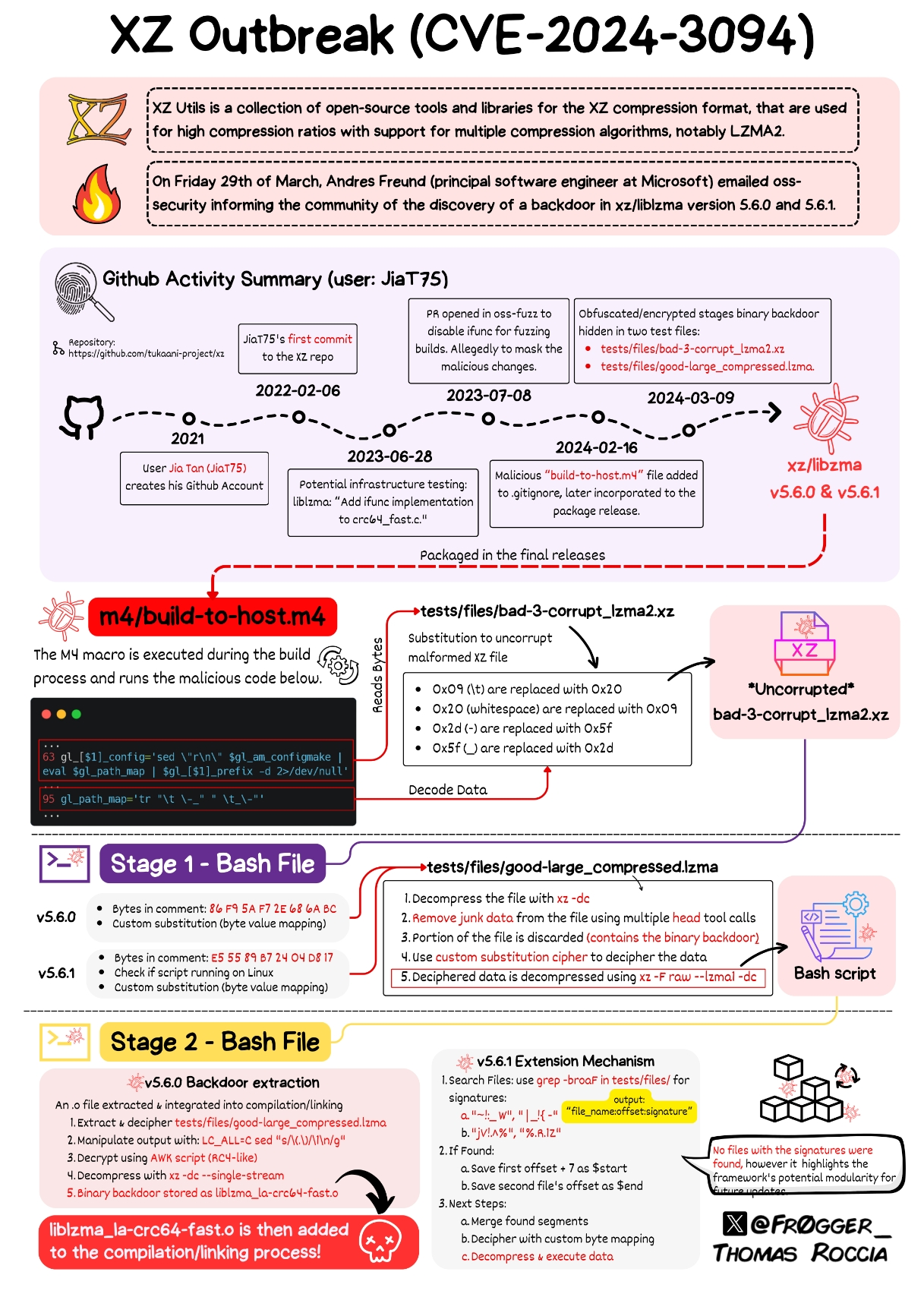
Because m4/build-to-host.m4, the entry point, is not in the git repo, but was included by the malicious maintainer into the tarballs.
The tarballs are the official distributions of the source code. The maintainer had git remove the malicious entry point when pushing the newest versions of the source code while retaining it inside these distributions.
All of this would be avoided if Debian downloaded from GitHub’s distributions of the source code, albeit unsigned.
I don’t understand the actual mechanics of it, but my understanding is that it’s essentially like what happened with Volkswagon and their diesel emissions testing scheme where it had a way to know it was being emissions tested and so it adapted to that.
The malicious actor had a mechanism that exempted the malicious code when built from source, presumably because it would be more likely to be noticed when building/examining the source.
Edit: a bit of grammar. Also, this is my best understanding based on what I’ve read and videos I’ve watched, but a lot of it is over my head.
The malicious code is not on the source itself, it’s on tests and other files. The building process hijacks the code and inserts the malicious content, while the code itself is clean, So the co-manteiner was able to keep it hidden in plain sight.
So it’s not that the Volkswagen cheated on the emissions test. It’s that running the emissions test (as part of the building process) MODIFIED the car ITSELF to guzzle gas after the fact. We’re talking Transformers level of self modification. Manchurian Candidate sleeper agent levels of subterfuge.
The malicious code wasn’t in the source code people typically read (the GitHub repo) but was in the code people typically build for official releases (the tarball). It was also hidden in files that are supposed to be used for testing, which get run as part of the official building process.
The malicious code was written and debugged at their convenience and saved as an object module linker file that had been stripped of debugger symbols (this is one of its features that made Fruend suspicious enough to keep digging when he profiled his backdoored ssh looking for that 500ms delay: there were no symbols to attribute the cpu cycles to).
It was then further obfuscated by being chopped up and placed into a pure binary file that was ostensibly included in the tarballs for the xz library build process to use as a test case file during its build process. The file was supposedly an example of a bad compressed file.
This “test” file was placed in the .gitignore seen in the repo so the file’s abscense on github was explained. Being included as a binary test file only in the tarballs means that the malicious code isn’t on github in any form. Its nowhere to be seen until you get the tarball.
The build process then creates some highly obfuscated bash scripts on the fly during compilation that check for the existence of the files (since they won’t be there if you’re building from github). If they’re there, the scripts reassemble the object module, basically replacing the code that you would see in the repo.
Thats a simplified version of why there’s no code to see, and that’s just one aspect of this thing. It’s sneaky.
Any additional information been found on the user?
Can’t confirm but unlikely.
Via https://boehs.org/node/everything-i-know-about-the-xz-backdoor
They found this particularly interesting as Cheong is new information. I’ve now learned from another source that Cheong isn’t Mandarin, it’s Cantonese. This source theorizes that Cheong is a variant of the 張 surname, as “eong” matches Jyutping (a Cantonese romanisation standard) and “Cheung” is pretty common in Hong Kong as an official surname romanisation. A third source has alerted me that “Jia” is Mandarin (as Cantonese rarely uses J and especially not Ji). The Tan last name is possible in Mandarin, but is most common for the Hokkien Chinese dialect pronunciation of the character 陳 (Cantonese: Chan, Mandarin: Chen). It’s most likely our actor simply mashed plausible sounding Chinese names together.

Just because somebody picked a vaguely Chinese-sounding handle doesn’t mean much about who or where.

They’re more likely to be based in Eastern Europe based on the times of their commits (during working hours in Eastern European Time) and the fact that while most commits used a UTC+8 time zone, some of them used UTC+2 and UTC+3: https://rheaeve.substack.com/p/xz-backdoor-times-damned-times-and
It is also hard to be certain as they could be a night owl or a early riser.

as long as you’re up to date on everything here: https://boehs.org/node/everything-i-know-about-the-xz-backdoor
the only additional thing i’ve seen noted is a possibilty that they were using Arch based on investigation of the tarball that they provided to distro maintainers
Don’t forget all of this was discovered because ssh was running 0.5 seconds slower

Its toooo much bloat. There must be malware XD linux users at there peak!
Tbf 500ms latency on - IIRC - a loopback network connection in a test environment is a lot. It’s not hugely surprising that a curious engineer dug into that.


Is that from the Microsoft engineer or did he start from this observation?
From what I read it was this observation that led him to investigate the cause. But this is the first time I read that he’s employed by Microsoft.

I’ve seen that claim a couple of places and would like a source. It very well may be since Microsoft prefers Debian based systems for WSL and for azure, but its not something I would have assumed by default
Technically that wasn’t the initial entrypoint, paraphrasing from https://mastodon.social/@AndresFreundTec/112180406142695845 :
It started with ssh using unreasonably much cpu which interfered with benchmarks. Then profiling showed that cpu time being spent in lzma, without being attributable to anything. And he remembered earlier valgrind issues. These valgrind issues only came up because he set some build flag he doesn’t even remember anymore why it is set. On top he ran all of this on debian unstable to catch (unrelated) issues early. Any of these factors missing, he wouldn’t have caught it. All of this is so nuts.

I have been reading about this since the news broke and still can’t fully wrap my head around how it works. What an impressive level of sophistication.
And due to open source, it was still caught within a month. Nothing could ever convince me more than that how secure FOSS can be.

Idk if that’s the right takeaway, more like ‘oh shit there’s probably many of these long con contributors out there, and we just happened to catch this one because it was a little sloppy due to the 0.5s thing’
This shit got merged. Binary blobs and hex digit replacements. Into low level code that many things use. Just imagine how often there’s no oversight at all
Yes, and the moment this broke other project maintainers are working on finding exploits now. They read the same news we do and have those same concerns.
I was literally compiling this library a few nights ago and didn’t catch shit. We caught this one but I’m sure there’s a bunch of “bugs” we’ve squashes over the years long after they were introduced that were working just as intended like this one.
The real scary thing to me is the notion this was state sponsored and how many things like this might be hanging out in proprietary software for years on end.


{kind=link}
{kind=link}